|
A dataset contains one or more tables that are being shown via data grids. An app can have another dataset that contains one or more tables that are not shown on the main view. The parser for dataset is not usually used because it is easier to parse the data grids where these dataset tables are stored and viewed. See Parse Data Grid Control for details.
The syntax for the dataset is as follows:
{Dataset.TableName.ColumnName.FunctionName.FilterExpression.FormatEnum}
Dataset = refers to the main dataset.
TableName = refers to the name of the table inside the dataset. This has the same name as data grid that holds the data table.
ColumnName = refers to the column name of the data grid.
FunctionName = refers to the function to be used when evaluating the value. The default function is "Value" which returns the value of the cell
FilterExpression = refers to the filter to be applied before retrieving the value of the control. This uses the ado.net datatable filter expression.
FormatEnum = refers to output format such as number format and date format.
Ex: {Dataset.BookSL.VatAmount.Value.RefNo='2018-1010'}
Dataset = refers to main dataset
BookSL = refers to the name of the table
Value = refers to the function to be used.
RefNo='2018-1010' = refers to the filter expression\
The syntax for the hidden dataset is almost the as the dataset syntax above. The only difference is the keyword "HiddenDateset" instead of "Dataset".
Syntax: {HiddenDataset.TableName.ColumnName.FunctionName.FilterExpression.FormatEnum}
The names of the tables of the dataset are the same as the names of the data grids and all the table records are stored in the data grids. It's recommended to parse the data grid instead of the data tables because the default row for dataset is the always the first row unlike with the data grid, the default row is the current row which is the row where you usually want to retrieve the value.
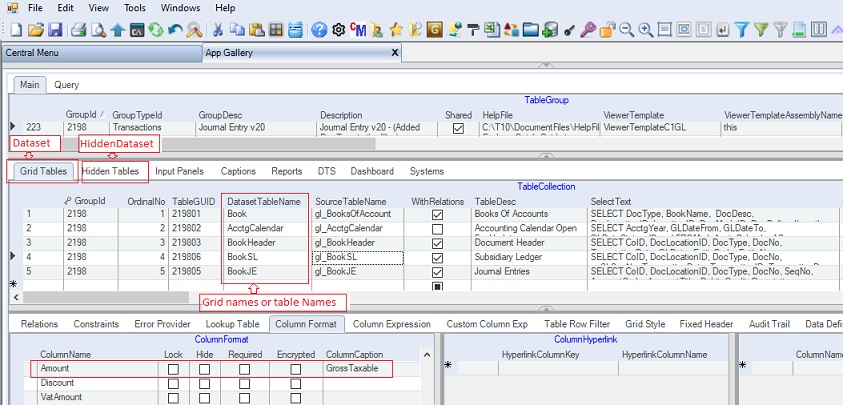
The image below shows the Dataset under the Grid Tables tab and the names of its tables under the DatasetTableName tab. The HiddenDataset is under the Hidden Tables tab.
|
|